Russia’s Prigozhin remains under investigation for mutiny
submitted by /u/MalborosInLondon [link] [comments]
More results...
submitted by /u/MalborosInLondon [link] [comments]
Three months after arresting its administrator, U.S. federal authorities seized the domain of the notorious hacking site BreachForums. For a time, the forum was the go-to community for English-speaking cybercriminals
Prime minister says ‘we have got to explain what it is about’ as he shrugs off polls showing slipping supportGet our morning and afternoon news emails, free app or daily news podcastAnthony Albanese has shrugged off polling results showing slipping sup…
CEO Kristin Stubbins says once internal investigation is complete there will be ‘appropriate accountability’ for those found to have acted inappropriatelyFollow our Australia news live blog for the latest updatesGet our morning and afternoon news email…
Intelligence sources have suggested that Yevgeny Prigozhin called off his planned Moscow takeover following threats to the families of Wagner mercenaries.
Hello everyone. Let’s say there is a website that hosts various PDF files you can access simply from your browser without any authentication. This is the URL for an example file:
example.org/files/XXXX-XXXX-XXXX-XXXX.pdf
If you guess the correct number (For example, 5326-4253-2512-6422.pdf), you will see the PDF. If you provide a number for a non-existing PDF, you will see this error: Imgur
I tried to just check random generated links with a Python script, but I realized this would take years because there are 9999999999999999 possible combinations (The first number is between 1 and 9, and the rest of the numbers are between 0 and 9).
Do you have any idea how I should find the good URLs? There are approximately 5000-15000 PDFs on the server. The links aren’t shared anywhere on the internet.
Thank you very much
submitted by /u/HerBalint
[link] [comments]
Research estimates that the Bank of England’s latest rate hike could see 1.2 million U.K. households run out of savings by the end of the year.
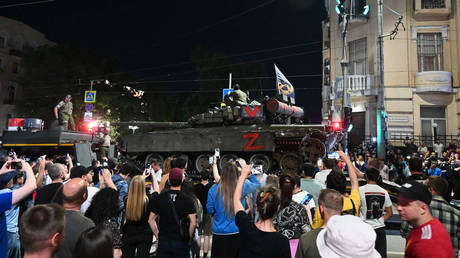 The US government predicted that Evgeny Prigozhin’s insurrection would be “a great deal more violent” than it transpired, CNN has reported
The US government predicted that Evgeny Prigozhin’s insurrection would be “a great deal more violent” than it transpired, CNN has reported
Read Full Article at RT.com
Yuval Mann / Ynetnews:
An interview with early Waze investors Yahal Zilka and Ehud Levy on why they invested, the impact of Google’s acquisition on Israel’s tech industry, and more — The disregard for map companies, the dilemma betw…
{kind=link}